Computer-Assisted Video Analysis Methods for Understanding Underrepresented Student Participation and Learning in Collaborative Learning Environments
Featured research

Jatla, V., Sravani T., Ugesh E., Sylvia C.P., and Marios S. P. "Fast Low-parameter Video Activity Localization in Collaborative Learning Environments." arXiv preprint arXiv:2403.01281 (2024).
The system processes the input videos using fast activity initializations and current methods for object detection to determine the location and the the person performing the activities. These regions are then processed through an optimal low-parameter dyadic 3D-CNN classifier to identify the activity. The proposed system processes 1 hour of video in 15 minutes for typing and 50 minutes for writing activities. The system uses several methods to optimize the inference pipeline. For each activity, the system determines an optimal low-parameter 3D CNN architecture selected from a family of low-parameter architectures. The input video is broken into smaller video regions that are transcoded at an optimized frame rate. For inference, an optimal batch size is determined for processing input videos faster. Overall, the low-parameter separable activity classification model uses just 18.7K parameters, requiring 136.32 MB of GPU memory and running at 4,620 (154 x 30) frames per second. Compared to current methods, the approach used at least 1,000 fewer parameters and 20 times less GPU memory, while outperforming in both inference speed and classification accuracy.

Wenjing S., Phuong T., Sylvia C.P., and Marios S.P. Long-term Human Participation Assessment In Collaborative Learning Environments Using Dynamic Scene Analysis. IEEE Access, 2024.
The proposed method of using multiple image representations is shown to perform equally or better than YOLO on all video instances. Over the entire dataset, the proposed method achieved an F1 score of 0.85 compared to 0.80 for YOLO. Following student group detection, the paper presents the development of a dynamic participant tracking system for assessing student group participation through long video sessions. The proposed dynamic participant tracking system is shown to perform exceptionally well, missing a student in just one out of 35 testing videos. In comparison, a state- of-the-art method fails to track students in 14 out of the 35 testing videos. The proposed method achieves 82.3% accuracy on an independent set of long, real-life collaborative videos.
Video Presentations
Tutorial 3: Large Scale Video Analytics
Marios S. Pattichis The University of New Mexico, USA Andreas Panayides The University of Cyprus, Cyprus
The Importance of the Instantaneous Phase in Detecting Faces with Convolutional Neural Networks
Large scale training of Deep Learning methods requires significant computational resources. The use of transfer learning methods tends to speed up learning while producing complex networks that are very hard to interpret. This paper investigates the use of a low-complexity image processing system to investigate the advantages of using AMFM representations versus raw images for face detection. Thus, instead of raw images, we consider the advantages of using AM, FM, or AM-FM representations derived from a low-complexity filterbank and processed through a reduced LeNet-5. The results showed that there are significant advantages associated with the use of FM representations. FM images enabled very fast training over a few epochs while neither IA nor raw images produced any meaningful training for such low-complexity network. Furthermore, the use of FM images was 7× to 11× faster to train per epoch while using 123× less parameters than a reduced-complexity MobileNetV2, at comparable performance (AUC of 0.79 vs 0.80)
Fast and Scalable 2D Convolutions and Cross-correlations for Processing Image Databases and Videos on CPUs
The dominant use of Convolutional Neural Networks (CNNs) in several image and video analysis tasks necessitates a careful re-evaluation of the underlying software libraries for computing them for large-scale image and video databases. We focus our attention on developing methods that can be applied to large image databases or videos of large image sizes. We develop a method that maximizes throughput through the use of vector-based memory I/O and optimized 2D FFT libraries that run on all available physical cores. We also show how to decompose arbitrarily large images into smaller, optimal blocks that can be effectively processed through the use of overlap-andadd. Our approach outperforms Tensorflow for 5x5 kernels and significantly outperforms Tensorflow for 11x11 kernels.
Publications
- Wenjing Shi, Phuong Tran, Sylvia Celedón-Pattichis, and Marios S Pattichis. Long-term Human Participation Assessment In Collaborative Learning Environments Using Dynamic Scene Analysis. IEEE Access, 2024.
- Antonio Gomez, Marios S Pattichis, and Sylvia Celedón-Pattichis. Speaker diarization and identification from single channel classroom audio recordings using virtual microphones. IEEE Access, 10:56256--56266, 2022.
- Tapia, L.S., Gomez, A., Esparza, M., Jatla, V., Pattichis, M.S., Celedón-Pattichis, S., and LópezLeiva, C. (2021, July)., Bilingual Speech Recognition by Estimating Speaker Geometry from Video Data The 19th International Conference on Computer Analysis of Images and Patterns (CAIP), 2021.
- Shi, W., Pattichis, M.S., Celedón-Pattichis, S., and LópezLeiva, C. (2021, July)., Talking Detection in Collaborative Learning Environments The 19th International Conference on Computer Analysis of Images and Patterns (CAIP), 2021.
- Tran, P., Pattichis, M.S., Celedón-Pattichis, S., and LópezLeiva, C. (2021, July)., Facial Recognition in Collaborative Learning Videos The 19th International Conference on Computer Analysis of Images and Patterns (CAIP), 2021.
- Teeparthi, S., Jatla, V., Pattichis, M.S., Celedón-Pattichis, S., and LópezLeiva, C. (2021, July)., Fast Hand Detection in Collaborative Learning Environments. The 19th International Conference on Computer Analysis of Images and Patterns (CAIP), 2021.
- Shi, W., Pattichis, M.S., Celedón-Pattichis, S., and LópezLeiva, C. (2021, July)., Person Detection in Collaborative Group Learning Environments Using Multiple Representations. 2021 Asilomar Conference on Signals, Systems, and Computers.
- Jatla, V., Teeparthi, S., Pattichis, M.S., Celedón-Pattichis, S., and LópezLeiva, C. (2021, July)., Long-term Human Video Activity Quantification of Student Participation. invited in 2021 Asilomar Conference on Signals, Systems, and Computers.
- Carranza, C., Llamocca, D., Pattichis, M. S. (2020, March)., Fast and Scalable 2D Convolutions and Cross-correlations for Processing Image Databases and Videos on CPUs. In 2020 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI)
- Sanchez Tapia, L., Pattichis, M. S., Celedón-Pattichis, S., & LópezLeiva, C. (2020, March)., The Importance of the Instantaneous Phase for Face Detection Using Simple Convolutional Neural Networks. In 2020 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI)
- Shi, W., Pattichis, M. S., Celedón-Pattichis, S., & LópezLeiva, C. (2018, October)., Dynamic Group Interactions in Collaborative Learning Videos. In 2018 52nd Asilomar Conference on Signals, Systems, and Computers (pp. 1528-1531).
- Stubbs, S., Pattichis, M., and Birch, G.,(2017) ., Interactive Image and Video Classification using Compressively Sensed Images. In 2017 Asilomar Conference on Signals, Systems, and Computers, (pp. 2038-2041).
- Jacoby, A., Pattichis, M., Celedón-Pattichis, S., and LópezLeiva, C. (2018, April)., Context-sensitive Human Activity Classification in Collaborative Learning Environments. 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI) (pp. 1-4).
- Shi, W., Pattichis, M., Celedón-Pattichis, S., and LópezLeiva, C. (2018). , Robust Head Detection in Collaborative Learning Environments using AM-FM Representations. In 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), (pp. 1-4).
- Eilar, C. W., Jatla V., Pattichis, M. S., LópezLeiva ,C., and Celedón-Pattichis S., “Ditributed video analysis for the advancing out of school learning in mathematics and engineering project” ., In 2016 50th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, 2016. (pp. 571-575).
Dissertaions

Jatla, V. "Long-term Human Video Activity Quantification in Collaborative Learning Environments." (2023).
Research on video activity detection has
mainly focused on identifying well-defined human activities in
short video segments, often requiring large-parameter systems
and extensive training datasets. This dissertation introduces
a low-parameter, modular system with rapid inference
capabilities, capable of being trained on limited datasets
without transfer learning from large-parameter systems. The
system accurately detects specific activities and associates
them with students in real-life classroom
videos. Additionally, an interactive web-based application is
developed to visualize human activity maps over long classroom
videos.
Long-term video activity detection in classrooms presents
challenges, such as multiple simultaneous activities, rapid
transitions, long-term occlusions, duration exceeding 15 minutes,
numerous individuals performing similar activities, and
differentiating subtle hand movements. The system employs fast
activity initialization, object detection methods, and a low-parameter
dyadic 3D-CNN classifier to process 1-hour videos in 15 minutes for
typing and 50 minutes for writing activities.
Optimizing the inference pipeline involves determining optimal
low-parameter 3D CNN architectures, trans-coding smaller video
regions at an optimized frame rate, and using an optimal batch size
for processing input videos. The resulting low-parameter model uses
18.7K parameters, requires 136.32 MB of memory, and runs at 4,620
frames per second, outperforming current methods in parameters, GPU
memory usage, inference speed, and classification accuracy.

Shi, W. "Long-term Human Participation Detection Using A Dynamic Scene Analysis Model." (2023).
The dissertation develops new methods for
assessing student participation in long (>1 hour) classroom
videos. First, the dissertation introduces the use of multiple
image representations based on raw RGB images and AM-FM
components to detect specific student groups. Second, a
dynamic scene analysis model is developed for tracking under
occlusion and variable camera angles. Third, a motion vector
projection system identifies instances of students talking.
The proposed methods are validated using digital videos from
the Advancing Out-of-school Learning in Mathematics and
Engineering (AOLME) project. The proposed methods are shown to
provide better group detection, and better talking detection
at 59% accuracy compared to 42% for Temporal Segment Network
(TSN) and 45% for Convolutional 3D neural network (C3D), and
dynamic scene analysis can track participants at 84.1%
accuracy compared to 61.9% for static analysis. The methods
are used to create activity maps to visualize and quantify
student participation.
Theses
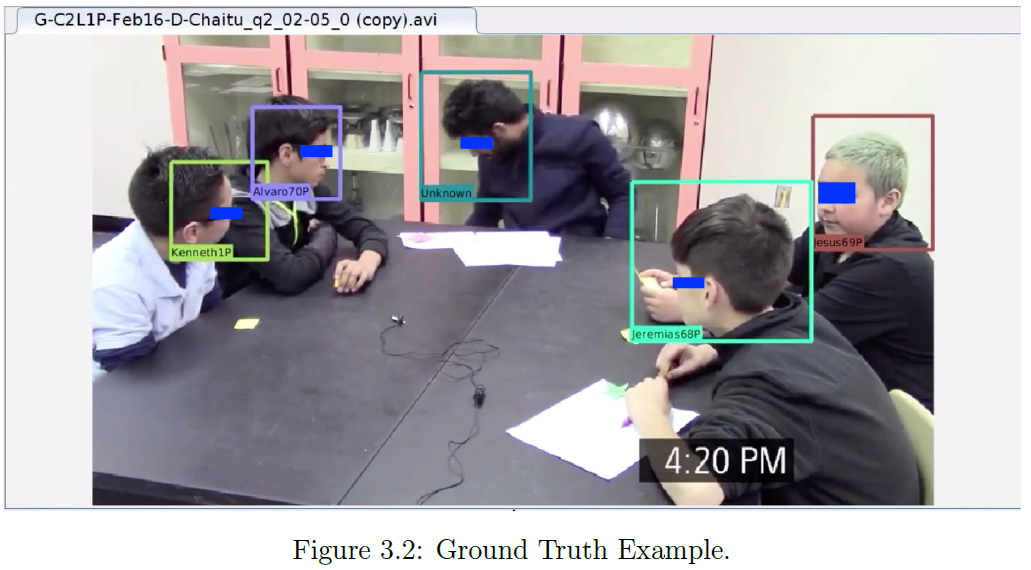
Tran, P. "Fast Video-based Face Recognition in Collaborative Learning Environments." (2021).
Face recognition is a classical problem in Computer Vision
that has experienced significant progress recently. Yet, face
recognition in videos remains challenging. In digital videos,
face recognition is complicated by occlusion, pose and
lighting variations, and persons entering and leaving the
scene. The goal of the thesis is to develop a fast method for
face recognition in digital videos that is applicable to large
datasets. Instead of the standard video-based methods that are
tested on short videos, the goal of the approach is to be
applicable to long educational videos of several minutes to
hours, with the ultimate goal of testing over a thousand hours
of videos. The thesis introduces several methods to address
the problems associated with video face recognition. First, to
address issues associated with pose and lighting variations, a
collection of face prototypes is associated with each
student. Second, to speed up the process, sampling, K-means
Clustering, and a combination of both are used to reduce the
number of face prototypes associated with each student.
Third, to further speed up the method, the videos are
processed at different frame rates. Fourth, the thesis
proposes the use of active sets to address occlusion and also
to eliminate the need to apply face recognition on video
frames with slow face motions. Fifth, the thesis develops a
group face detector that recognizes students within a
collaborative learning group, while rejecting out-of-group
face detections. Sixth, the thesis introduces a face DeID for
protecting the identities of the students. Seventh, the
thesis uses data augmentation to increase the size of the
training set. The different methods are combined using
multi-objective optimization to guarantee that the full method
remains fast without sacrificing accuracy. To test the
approach, the thesis develops the AOLME dataset that consists
of 138 student faces with 81 boys and 57 girls of ages 10 to
14, which were predominantly Latina/o students. The video
dataset consists of 3 Cohorts, 3 Levels from two schools
(Urban and Rural) throughout the course of 3 years. Each
Cohort and Level contain multiple sessions and an average of 5
small groups of 4 students per school. Each session has from
4 to 9 videos that average 20 minutes each. The thesis trained
on different video clips for recognizing 32 different students
from both schools. The training and validation datasets
consisted of 22 different sessions, whereas the test set
contained videos from seven other sessions. Different sessions
were used for training, validation, and testing. The video
face recognition was tested on 13 video clips extracted from
different groups, with a duration that ranges from 10 seconds
to 10 minutes. Compared to the baseline method, the final
optimized method resulted in very fast recognition times with
significant improvements in face recognition accuracy. Using
face prototype sampling only, the proposed method achieved an
accuracy of 71.8% compared to 62.3% for the baseline system,
while running 11.6 times faster.
Esparza P., Mario J. "Spanish and English Phoneme Recognition by Training on Simulated Classroom Audio Recordings of Collaborative Learning Environments." (2021).
Audio recordings of collaborative learning environments contain a constant presence
of cross-talk and background noise. Dynamic speech recognition between Spanish and
English is required in these environments. To eliminate the standard requirement
of large-scale ground truth, the thesis develops a simulated dataset by transforming
audio transcriptions into phonemes and, using 3D speaker geometry and data
augmentation to generate an acoustic simulation of Spanish and English speech.
The thesis develops a low-complexity neural network for recognizing Spanish and
English phonemes (available at github.com/muelitas/keywordRec). When trained on
41 English phonemes, 0.099 PER is achieved on Speech Commands. When trained on
36 Spanish phonemes and tested on real recordings of collaborative learning environments,
a 0.7208 LER is achieved. Slightly better than Google’s Speech-to-text 0.7272
LER, which used anywhere from 15 to 1,635 times more parameters and trained on
300 to 27,500 hours of real data as opposed to 13 hours of simulated audios.

Sravani T., "Long Term Object Detection and Tracking in Collaborative Learning Environments", (2021)
Long-term object detection requires the integration of frame-
based results over several seconds. For non-deformable objects, long-term
detection is often addressed using object detection followed by video
tracking. Unfortunately, tracking is inapplicable to objects that undergo
dramatic changes in appearance from frame to frame. As a related ex-
ample, we study hand detection over long video recordings in collab-
orative learning environments. More specifically, we develop long-term
hand detection methods that can deal with partial occlusions and dra-
matic changes in appearance.
Our approach integrates object-detection, followed by time projections,
clustering, and small region removal to provide effective hand detection
over long videos. The hand detector achieved average precision (AP) of
72% at 0.5 intersection over union (IoU). The detection results were im-
proved to 81% by using our optimized approach for data augmentation.
The method runs at 4.7×the real-time with AP of 81% at 0.5 intersection
over the union. Our method reduced the number of false-positive hand
detections by 80% by improving IoU ratios from 0.2 to 0.5. The overall
hand detection system runs at 4× real-time.

Sanchez T. "The Importance of the Instantaneous Phase in Detecting Faces with Convolutional Neural Networks." (2019).
This thesis considers the problem of detecting faces
from the AOLME video dataset.This thesis examines the
impact of using the instantaneous phase for the AOLME block-based
face detection application. For comparison, the thesis compares the
use of the Frequency modulation image based on the instantaneous phase,
the use of the instantaneous amplitude, and the original gray scale image. To generate the FM and
AM inputs, the thesis uses dominant component analysis that aims to decrease the training overhead
while maintaining interpretability.
The results indicate that the use of the FM image yielded about the same performance as the
MobileNet V2 architecture (AUC of 0.78 vs 0.79), with vastly reduced training times
Training was 7x faster for an Intel Xeon with a GTX 1080 based desktop and 11x faster on a
laptop with Intel i5 with a GTX 1050. Furthermore, the proposed
architecture trains 123x less parameters than what is needed for MobileNet V2.

Darsey, C.J. "Hand movement detection in collaborative learning environment videos." (2018).
This thesis explores detection of hand movement using color and optical flow.
Exploratory analysis considered the problem component wise on components created
from thresholds applied to motion and color. The proposed approach uses patch
color classification, space-time patches of video, and histogram of optical flow. The
approach was validated on video patches extracted from 15 AOLME video clips. The
approach achieved an average accuracy of 84% and an average receiver operating
characteristic area under curve (ROC AUC) of 89%.
UNM Digital repository
Download Software

Jacoby, A. R. "Context-Sensitive Human Activity Classification in Video Utilizing Object Recognition and Motion Estimation." (2017).
This thesis explores the use of color based object detection in conjunction with
contextualization of object interaction to isolate motion vectors specific to an activity
sought within uncropped video. Feature extraction in this thesis differs significantly
from other methods by using geometric relationships between objects to infer con-
text. The approach avoids the need for video cropping or substantial preprocessing
by significantly reducing the number of features analyzed in a single frame. The
method was tested using 43 uncropped video clips with 620 video frames for writing,
1050 for typing, and 1755 frames for talking. Using simple KNN classification, the
method gave accuracies of 72.6% for writing, 71% for typing and 84.6% for talk-
ing. Classification accuracy improved to 92.5% (writing), 82.5% (typing) and 99.7%
(talking) with the use of a trained Deep Neural Network.
UNM Digital repository
Download Software

Shi, W. "Human Attention Detection Using AM-FM Representations." (2016).
The thesis explores phase-based solutions for (i) detecting faces,
(ii) back of the heads, (iii) joint detection of faces and back of the heads, and (iv)
whether the head is looking to the left or the right, using standard video cameras
without any control on the imaging geometry. The proposed phase-based approach
is based on the development of simple and robust methods that relie on the use of
Amplitude Modulation - Frequency Modulation (AM-FM) models.For the students facing the camera,
the method was able to correctly classify 97.1% of them looking to the left and 95.9%
of them looking to the right. For the students facing the back of the camera, the
method was able to correctly classify 87.6% of them looking to the left and 93.3%
of them looking to the right. The results indicate that AM-FM based methods hold
great promise for analyzing human activity videos.
UNM Digital repository
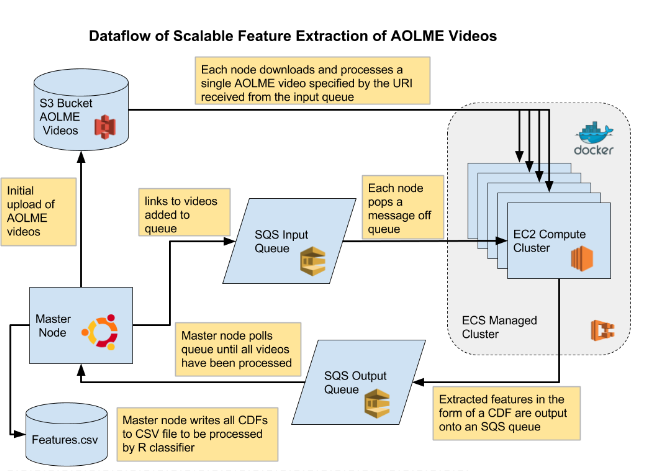
Eilar, C. W. "Distributed and scalable video analysis architecture for human activity recognition using cloud services." (2016).
This thesis proposes an open-source, maintainable system for detecting human
activity in large video datasets using scalable hardware architectures. The system
is validated by detecting writing and typing activities that were collected as part of
the Advancing Out of School Learning in Mathematics and Engineering (AOLME)
project. The implementation of the system using Amazon Web Services (AWS)
is shown to be both horizontally and vertically scalable. The software associated
with the system was designed to be robust so as to facilitate reproducibility and
extensibility for future research.
UNM Digital repository
Franco, C. "Lesson Plan and Workbook for Introducing Python Game Programming to Support the Advancing Out-of-School Learning in Mathematics and Engineering (AOLME) Project." (2014).
The Advancing Out-of-School Learning in Mathematics and Engineering
(AOLME) project was created specifically for providing integrated mathematics and
engineering experiences to middle-school students from under-represented groups.
The thesis presents a new approach to introducing game programming to middle
-school students that have undergone AOLME-training while still maintaining a fun
and relaxed environment. The thesis provides a discussion of three different
educational, visual-programming environments that are also designed for younger
programmers and provides motivation for the proposed approach based on Python.
The thesis details interactive activities that are intended for supporting the students
to develop their own games in Python.
UNM Digital repository
Non-IRB Material

Talking/No Talking (trimmed) Writing/No Writing (trimmed)
Projects
Undergraduate Projects
GitHub
Patent
Acknowledgements
Some of the material is based upon work supported by the National Science Foundation under Grant No. 1613637 and No. 1842220. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation